目录
1. kube proxy规则同步高延迟现象
在一次重启coredns时,我们发现有些解析失败的现象,由此怀疑到可能是kube proxy更新ipvs或iptables规则慢导致的。
查看kube proxy的监控图,也确实发现有偶尔非常慢的问题,如下图所示:
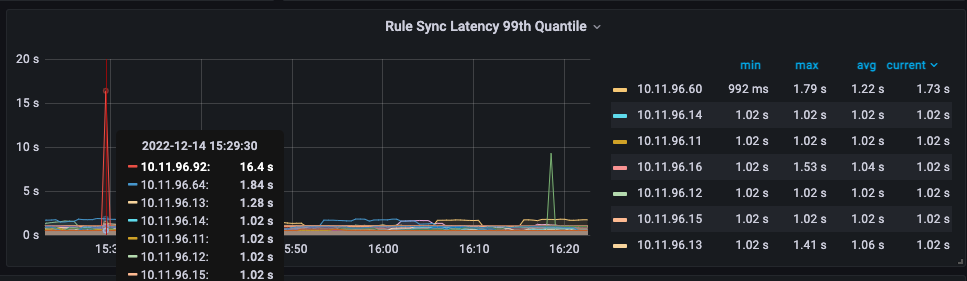
可以看到10.11.96.92这个节点显示规则同步的99线为16.4s。如果这个时间是真的,那肯定是不能接受的一个延迟时间。正常来说应该不应该超过1s。
在一次重启coredns时,我们发现有些解析失败的现象,由此怀疑到可能是kube proxy更新ipvs或iptables规则慢导致的。
查看kube proxy的监控图,也确实发现有偶尔非常慢的问题,如下图所示:
可以看到10.11.96.92这个节点显示规则同步的99线为16.4s。如果这个时间是真的,那肯定是不能接受的一个延迟时间。正常来说应该不应该超过1s。
可以通过AWS命令或AWS控制台创建kops用户组及用户.
因现在已经有一台操作机,操作机已经有绑定IAM Role,其有全部的AWS权限,所以使用AWS命令创建:
[ec2-user@ip-172-31-3-142 ~]$ aws iam create-group --group-name kops
{
"Group": {
"Path": "/",
"CreateDate": "2021-05-17T07:03:18Z",
"GroupId": "AGPAW5FY7AWUKCOI3KGNK",
"Arn": "arn:aws:iam::474981795240:group/kops",
"GroupName": "kops"
}
}
[ec2-user@ip-172-31-3-142 ~]$ aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/AmazonEC2FullAccess --group-name kops
[ec2-user@ip-172-31-3-142 ~]$ aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/AmazonRoute53FullAccess --group-name kops
[ec2-user@ip-172-31-3-142 ~]$ aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/AmazonS3FullAccess --group-name kops
[ec2-user@ip-172-31-3-142 ~]$ aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/IAMFullAccess --group-name kops
[ec2-user@ip-172-31-3-142 ~]$ aws iam attach-group-policy --policy-arn arn:aws:iam::aws:policy/AmazonVPCFullAccess --group-name kops
[ec2-user@ip-172-31-3-142 ~]$ aws iam create-user --user-name kops
{
"User": {
"UserName": "kops",
"Path": "/",
"CreateDate": "2021-05-17T07:04:05Z",
"UserId": "AIDAW5FY7AWUOPCWZEIKU",
"Arn": "arn:aws:iam::474981795240:user/kops"
}
}
[ec2-user@ip-172-31-3-142 ~]$ aws iam add-user-to-group --user-name kops --group-name kops
[ec2-user@ip-172-31-3-142 ~]$ aws iam create-access-key --user-name kops
{
"AccessKey": {
"UserName": "kops",
"Status": "Active",
"CreateDate": "2021-05-17T07:04:22Z",
"SecretAccessKey": "xxxxxxxxxx",
"AccessKeyId": "xxxxxxxx"
}
}
记住上面的AccessKeyId及SecretAccessKey,后面能用得到。注意:私有密钥只能在创建时进行查看或下载。如果您的现有私有密钥放错位置,请创建新的访问密钥。
下载YAML部署Eventing CRD以及Core:
wget https://github.com/knative/eventing/releases/download/v0.24.0/eventing-crds.yaml
wget https://github.com/knative/eventing/releases/download/v0.24.0/eventing-core.yaml
sed -i 's/gcr.io/gcr.tencentcloudcr.com/g' eventing-core.yaml
kubectl apply -f ./eventing-crds.yaml
kubectl apply -f ./eventing-core.yaml
knative 详细配置
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
# 这是service名
name: hello
spec:
template:
metadata:
# 这是revision名,格式为{service-name}-{revision-name}
name: hello-world-two
# 软并发限制,并发瞬间变大时,可能超过此值
annotations:
# 自动扩缩容的类 "kpa.autoscaling.knative.dev" or "hpa.autoscaling.knative.dev"
autoscaling.knative.dev/class: "kpa.autoscaling.knative.dev"
# 自动扩缩容指标,"concurrency" ,"rps"或"cpu" cpu指标仅在具有 HPA,依赖上一个
autoscaling.knative.dev/metric: "concurrency"
# 上一个配置为concurrency表示并发超过200时进行扩容,上一个配置为rps表示超过200请求每秒时进行扩容,上一个配置为cpu表示cpu百分比
autoscaling.knative.dev/target: "200"
# 目标突发容量
autoscaling.knative.dev/targetBurstCapacity: "200"
# 目标利用率 允许达到硬限制的80%时进行扩建,但另外20%的流量还是发到此服务上
autoscaling.knative.dev/targetUtilizationPercentage: "80"
# 局部ingress入口类,会以局部为准,没有局部时用全局配置ConfigMap/config-network中的配置
networking.knative.dev/ingress.class: <ingress-type>
# 局部证书类入口,会以局部为准,没有局部时用全局配置ConfigMap/config-network中的配置,默认cert-manager.certificate.networking.knative.dev
networking.knative.dev/certifcate.class: <certificate-provider>
# 将流量逐步推出到修订版 先从1%开始,之后是与18%递增推进,是基于时间的,不与自动缩放子系统交互
serving.knative.dev/rolloutDuration: "380s"
# 每个修订版应具有的最小副本数 默认值: 0 如果启用缩放到零并使用类 KPA
autoscaling.knative.dev/minScale: "3"
# 每个修订应具有的最大副本数 0表示无限制
autoscaling.knative.dev/maxScale: "3"
# 修订在创建后必须立即达到的初始目标 创建 Revision 时,会自动选择初始比例和下限中较大的一个作为初始目标比例。默认: 1
autoscaling.knative.dev/initialScale: "0"
# 缩减延迟指定一个时间窗口,在应用缩减决策之前,该时间窗口必须以降低的并发性通过。
autoscaling.knative.dev/scaleDownDelay: "15m"
# 自动缩放配置模式--稳定窗口 在缩减期间,只有在稳定窗口的整个持续时间内没有任何流量到达修订版后,才会删除最后一个副本。
autoscaling.knative.dev/window: "40s"
# 自动缩放配置模式--紧急窗口 评估历史数据的窗口将如何缩小例如,值为10.0意味着在恐慌模式下,窗口将是稳定窗口大小的 10%。1.0~00.0
autoscaling.knative.dev/panicWindowPercentage: "20.0"
# 恐慌模式阈值 定义 Autoscaler 何时从稳定模式进入恐慌模式。 流量的百分比
autoscaling.knative.dev/panicThresholdPercentage: "150.0"
spec:
# 硬限制,流量过大时,将多余的流量转到缓存层上
containerConcurrency: 50
containers:
- image: gcr.io/knative-samples/helloworld-go
ports:
- containerPort: 8080
env:
- name: TARGET
value: "World"
resources:
requests:
cpu: 100m
memory: 640M
limits:
cpu: 1
traffic:
- latestRevision: true
percent: 80
# hello-world为revision名
- revisionName: hello-world
percent: 20
# 通过tag进行访问,访问地址 staging-<route name>.<namespace>.<domain>
tag: staging
修改helloworld-go.yaml,将"Go Sample v1"改成"Go Sample v2":
apiVersion: serving.knative.dev/v1
kind: Service
metadata:
name: helloworld-go
namespace: example
spec:
template:
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/knative-sample/helloworld-go:160e4dc8
env:
- name: TARGET
value: "Go Sample v2"
knative 是谷歌牵头的 serverless 架构方案,旨在提供一套简单易用的 serverless 开源方案,把 serverless 标准化和平台化。目前参与 knative 项目的公司主要有: Google、Pivotal、IBM、Red Hat和SAP。
早期版本有以下Knative组件:
因某些原因,2019年Build组年已经发展成一个独立项目Tekton,所以Knative现在主要由两个部分组成,Knative Serving以及Knative Eventing.
我的个人博客从WordPress迁移至Hugo后,每次写完新的blog发布变成了一件很麻烦的事,需要这么几步:
hugo server -D看效果hugo -D生成部署文件最后一步最烦,所花的时间也最久。
在网上查了一下hugo自动部署到ftp,还是有办法的: