php连接memcached使用短连接造成cpu过高
最近上线的一个项目,开始几天运行良好,负载很底,访问速度也很正常。
29号晚上发现在监控内web服务器有点不正常,cpu和负载会突然增高,然后过十来分钟就会恢复正常。ssh连上去看,有几个php-cgi进程cpu的使用是100%。当时怀疑可能是有个别程序没写好,就通知开发这边去查了。从下图可以看到:
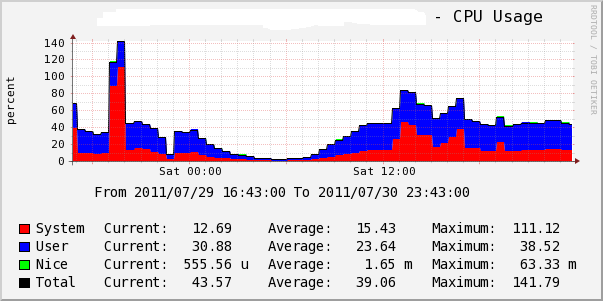
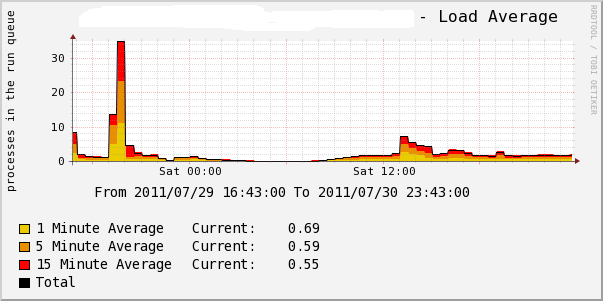
随着访问量的增加,到了昨天,好几台web都出现这种现象,并且cpu和负载都下不去了。一直是很高的状态。像下图这样:
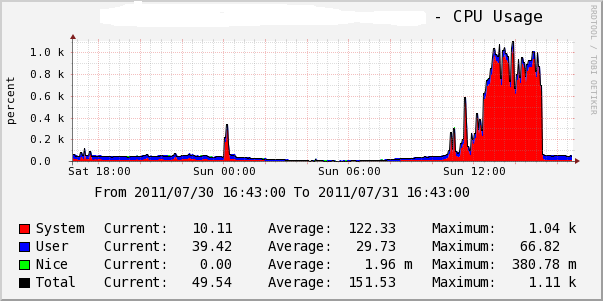
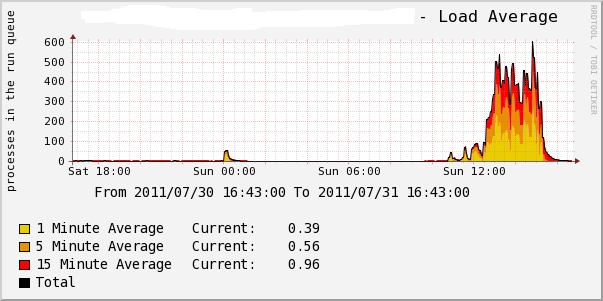
这就不正常了,用top看资源利用率,%us和%sy还在正常状态,10%以内,就是%si一直会很高,50%~90%。
开始感觉不像是代码没写好了,因为php+memcached+mysql的架构在其它项目上也跑得挺正常的。
top显示的si是指软中断,软中断会使用cpu资源。
看到软中断过高开始怀疑是不是网卡驱动不好,因为以前碰到过有些网卡只会用到一个cpu的软中断,查了查也不是。
那到底是什么使用了这么多的软中断呢?就怀疑是网络连接了,用netstat -anpo | grep :11211 | awk -F" " '{print $6}' | sort |uniq -c | sort -rn看了一下,发现time_out状态的连接超多。正常不应该有这么多的。
到这里直接就去查php代码了,发现连接代码如下:
$handle = new Memcache();
$handle->connect($config['host'], $config['port']);
用的是connect,这个是短连接。
理理头绪:为什么软中断会这么高?
因为php连接memcache使用短连接方式,这种方式是每次连上memcached,读写操作完成后,连接关闭,下次需要读写memcache时再重新连。由于php读写memcache特别频繁,自然php连接memcache的次数也就非常多了。而新建连接是需要代价的,会产生软中断。所以就在top内看到%si一直会很高,50%~90%。
基本确定原因后,改代码:
$handle = new Memcache();
$handle->pconnect($config['host'], $config['port']);
用pconnect,也就是长连接去连memcached,这样每个php进程只要建立一次连接,后面都可以重复利用这个连接。
再看服务器,在top内看到%si使用不到1%,cpu和负载都下来了。